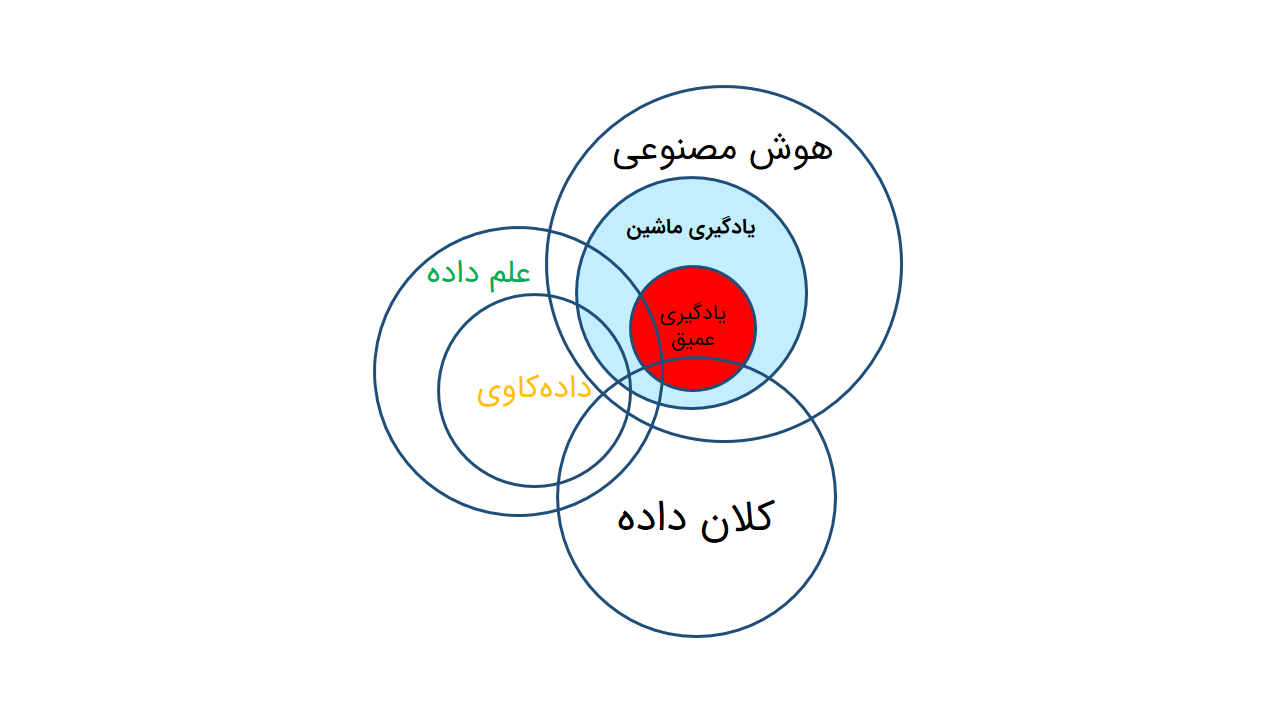
اجزا و ماهیت علم داده در یک نگاه
علم داده، علم استفاده از روشهای کمی آمار و ریاضیات در بستر تکنولوژی است که به منظور توسعه الگوریتمهای طراحی شده، کشف الگوها، پیشبینی نتایج و یافتن راهحلهای بهینه برای مسائل پیچیده کاربرد دارد (۱). در ادامه تلاش میکنیم تا مفاهیم علوم داده را در یک قاب نشان دهیم و پازل علم داده را که از ارتباط بین مفاهیم کلیدی متعدد تشکیل شدهاست، تبیین نماییم. از آنجایی که مفاهیم توسعه یافته در این حوزه بسیار هستند به جایگاه برخی موارد کلیدی و ارتباط آنها با یکدیگر میپردازیم:
در یک نگاه میتوان این پازل را به سه بخش هوش مصنوعی، کلان داده و دادهکاوی تقسیم نمود. سادهانگارانه خواهد بود اگر در جستجوی مرز دقیقی بین این بخشها باشیم و از اشتراک آنها غفلت کنیم. لازم است پیش از ورود به این مبحث به این نکته توجه شود که مفاهیم این حوزه بهطور پیچیدهای به یکدیگر گره خوردهاند و اختلاف نظر زیادی در دستهبندیها وجود دارد. از طرفی اگرچه تشریح مستقل مفاهیمی چون هوش مصنوعی، دادهکاوی و یادگیری ماشین و … تصویر روشنی در ذهن ایجاد مینماید اما بیش از آن باید به رابطه معناداری که در ترکیب این روشها برای کسب نتایج دقیقتر شکل میگیرد توجه داشت.
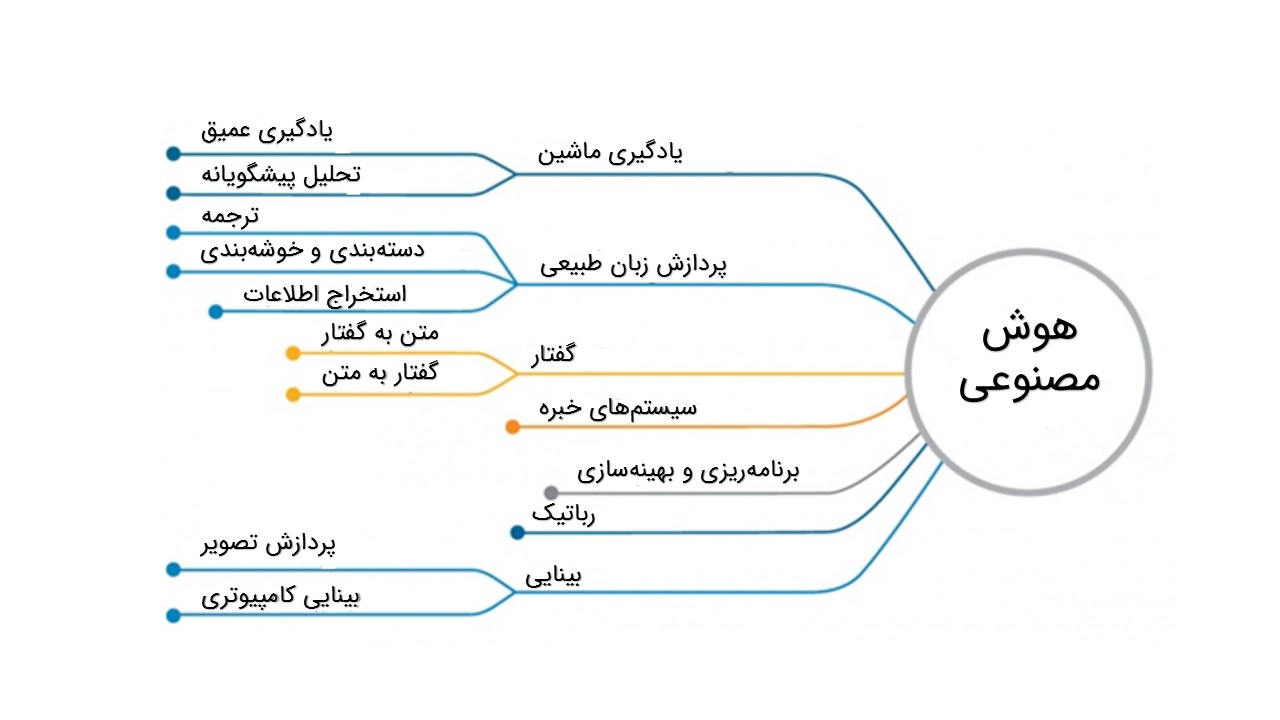
هوش مصنوعی به سیستمهایی گفته میشود که میتوانند واکنشهایی مشابه رفتارهای هوشمند انسانی داشته باشند از جمله درک شرایط پیچیده، توانایی کسب دانش، یادگیری و استدلال برای حل مسائل، شبیهسازی فرایندهای تفکری و شیوههای استدلالی انسان و پاسخ موفق به آنها. بیشتر نوشتهها و مقالههای مربوط به هوش مصنوعی، آن را به عنوان «دانش شناخت و طراحی عاملهای هوشمند» تعریف کردهاند (۲). بسیاری از مفاهیم مانند یادگیری ماشین و یادگیری عمیق بهگونهای از طریق هوش مصنوعی توسعه یافتهاند. اگرچه میتوان از هوش مصنوعی بدون بهکارگیری یادگیری ماشین نیز استفاده نمود اما بهاین منظور باید به میلیونها خط کد با قواعد و درختهای تصمیم پیچیده روی آورد (۳)!
شکل زیر شاخههای موجود در هوش مصنوعی را به تصویر کشیده است.
یادگیری ماشین طبق تعریف Tom Mitchell، به این سوال پاسخ میدهد که چگونه برنامههای کامپیوتری از طریق تجربه و یادگیری برای عملکرد خودکار توسعه یابند. در اینکه یادگیری ماشین بخشی از هسته مرکزی علم داده است شکی وجود ندارد، اما اگر از سطح بالاتری به موضوع بنگرید هدف علم داده استخراج دانش از داده است و یادگیری ماشین موتوری است که به این فرآیند اجازه میدهد تا به صورت خودکار انجام شود. از طرفی یادگیری ماشین ارتباط در هم تنیدهای با دادهکاوی دارد (۴). تکنیکهای پردازش داده سنتی محدودیتهای فراوانی در پردازش کلان دادهها دارند و برای دستیابی به تحلیلهای دقیق و بلادرنگ (real-time) به تکنیکهای پیچیده یادگیری ماشین نیاز است.
از روشهای یادگیری ماشین میتوان به یادگیری آینده (representation/future learning)، یادگیری عمیق، یادگیری موازی یا توزیعشده (distributed or parallel learning)، یادگیری انتقال، یادگیری فعال، یادگیری کرنل (kernel-based learning) اشاره کرد (۵).
یادگیری عمیق، فرآیند بهکارگیری تکنولوژی شبکه عصبی عمیق یعنی استفاده از معماری شبکه عصبی با لایههای پنهان متعدد در راستای حل مسائل است (۴). یادگیری عمیق کارکردی از هوش مصنوعی است که عملکرد مغز انسان در پردازش اطلاعات و تصمیمگیری با خلق الگوها را تقلید میکند. یادگیری عمیق زیرشاخهای از یادگیری ماشین در هوش مصنوعی است که قابلیت یادگیری بدون نظارت از دادههای غیرساختیافته و بدون برچسب را دارد. افزونبراین یادگیری عمیق در یادگیری بانظارت نیز بهطور گستردهای کاربرد دارد. یادگیری عمیق همچنین به عنوان یادگیری عصبی عمیق (Deep Neural Learning) یا شبکه عصبی عمیق (Deep Neural Network) نیز شناخته میشوند (۶).
یادگیری عمیق مراحل شبکهی عصبی را بهینه میکند تا فرآیند یادگیری ماشین انجام شود. شبکههای عصبی مصنوعی مانند مغز انسان از گرههای عصبی تشکیل شدهاند که در یک شبکه به یکدیگر متصل هستند. اولین لایه شبکه عصبی دادههای خام را پردازش میکند و آنها را به عنوان خروجی به لایه بعد منتقل میکند. لایه دوم اطلاعات لایه قبل را به اضافه اطلاعات بیشتر پردازش میکند و اطلاعات را به عنوان خروجی به لایه بعد انتقال میدهد و به همین ترتیب در هر لایه الگوها بهبود مییابند و مراحل شبکه عصبی طی میشود (۶).
الگوریتمها و معماریهای یادگیری عمیق، در سالهای اخیر قادر بودهاند پیشرفتهای شگرفی در زمینههای پردازش تصویر و گفتار به وجود آوردند. در ابتدا کاربرد آنها در پردازش زبان طبیعی (NLP) محدود بود اما امروزه ثابت نمودهاند تاثیر قابل توجهی بر نتایج بسیاری از حوزهها چون رباتیک، سلامت، امنیت فضای سایبری، بینایی کامپیوتری، درک احساسات و … داشته است.
تفاوت اصلی یادگیری عمیق با یادگیری ماشین در این است که یادگیری عمیق میتواند الگوها و وابستگیها را تا حدی پیچیده نماید که هیچ الگوریتم دیگری قادر به شناسایی نباشد. اگرچه این نتیجه با هزینههای محاسباتی بالا و پیچیدگیهای مهندسی روبهرو است اما به ما اجازه میدهد تا به مسائل تازهای در دادهکاوی که پیش از این بهندرت حل میشد پاسخ دهیم (۷) مانند:
- پردازش تصویر و گفتار
- تحلیلهای سری زمانی پیچیده
- نگاشتهای غیرخطی به منظور کاهش بعد
در حال حاضر یادگیری عمیق میتواند برای هر وظیفهای که سایر الگوریتمهای یادگیری ماشین ایفا میکنند، استفاده شود؛ این موارد شامل دستهبندی، کاهش بعد، شناسایی اشیا، خوشهبندی و غیره است و یادگیری عمیق برای دادههایی با ابعاد بالا همچون متن، تصویر و صوت توسعه یافته است (۷).
شبکههای باور عمیق یا Deep belief networks (DBNs) و شبکههای عصبی کانولوشنی (پیچشی) یا Convolutional neural networks (CNNs) از اصلیترین رویکردها و مسیرهای تحقیقاتی در دهههای اخیر هستند که بهخوبی در حوزه یادگیری عمیق ظاهر شدهاند و نوید آیندهای روشن را در این حوزه میدهند (۸).
با گسترش هر روزه حجم دادهها، به خصوص با افزایش قدرت پردازش در پردازندههای تصویری، یادگیری عمیق نقش محوری در ارائه راهحلهای پیشبینانه در پایگاه دادههای عظیم بازی میکند. برای مثال کامپیوتر مغزمانند آیبیام و مترجم زبان بیدرنگ (real-time) مایکروسافت که در جستجوگر صوتی بینگ استفاده میشود از تکنیکهای یادگیری عمیق برای استفاده از کلان داده بهعنوان مزیت رقابتی بهره میبرند (۸). یادگیری عمیق در واقع گامی بزرگ به سمت هوش مصنوعی میباشد و علاوه بر ارائه راهحلهای پیچیده مورد استفاده در فعالیتهای هوش مصنوعی، ماشینها را مستقل از دانش انسانی مینماید که در واقع همان هدف نهایی هوش مصنوعی است (۹).
کلان داده راهی برای توصیف انبوهی از اطلاعات است که سازمانها به منظور تبدیل دادههای خود به دانش با آن مواجه هستند (۱۰) و به دادههایی اطلاق میگردد که بسیار انبوه، پرشتاب و گوناگون هستند و نیاز به روشهای پردازشی تازهای دارند تا تصمیمگیری، بینش تازه و بهینگی پردازش پیشرفته را فراهم آورند. برای مثال کلان داده عنصر کلیدی برای هوش مصنوعی بهشمار میرود، بدین ترتیب استفاده موثر از هوش مصنوعی بهمیزان زیادی به وسعت و کیفیت دادههای موجود برای یادگیری و آزمون بستگی دارد (۱۱). در نتیجه دادهکاوی و هوش مصنوعی و همین طور سایر ابزار و روشها در مواجه با کلان داده ممکن است شکل تازهایی به خود بگیرند.
دادهکاوی را میتوان در نگاه کلی کاربرد الگوریتمهای خاص به منظور استخراج الگو از دادهها دانست (۴). در واقع دادهکاوی روشی برای اثبات یک فرضیه نیست بلکه روشی به منظور شکلگیری فرضیات مختلف است. دادهکاوی میتواند پاسخ سوالاتی که ممکن است تا به حال به آن فکر نکردهاید را آشکار کند. الگوها کدام هستند؟ کدام یک از آمار حیرتآور هستند؟ همبستگی بین A و B چیست؟ (۱۲) دادهکاوی فرآیندی محاسباتی از کشف الگوها در دادههای عظیم است که در روشهایی با هوش مصنوعی، یادگیری ماشین، آمار و پایگاههای داده نیز تعامل دارد (۷).
دادهکاوی میتواند اطلاعات موجود از منابع را به الگوهای برجسته تبدیل نماید و این الگوها را به عنوان پایهی کار به هوش مصنوعی و یادگیری ماشین ارائه دهد. یادگیری ماشین، هنر و علم یادگیری از دادهها بدون برنامهنویسی مستقیم است درحالی که دادهکاوی فرآیند یادگیری از داده است (۱۲). دادهکاوی به فعالیت ورود به پایگاه دادههای عظیم به منظور جستجو در اطلاعات مرتبط میباشد؛ که مصداق روشنی از مثل «پیدا کردن سوزن در انبار کاه» است. از آنجایی که تصمیمگیرندهگان به دادههای کم حجم و خاصشده نیاز دارند از دادهکاوی برای کشف بخشهای اطلاعاتی استفاده میکنند. درواقع کلان داده دارایی اصلی است و داده کاوی مبدل این دارایی به نتایج سودمند است.
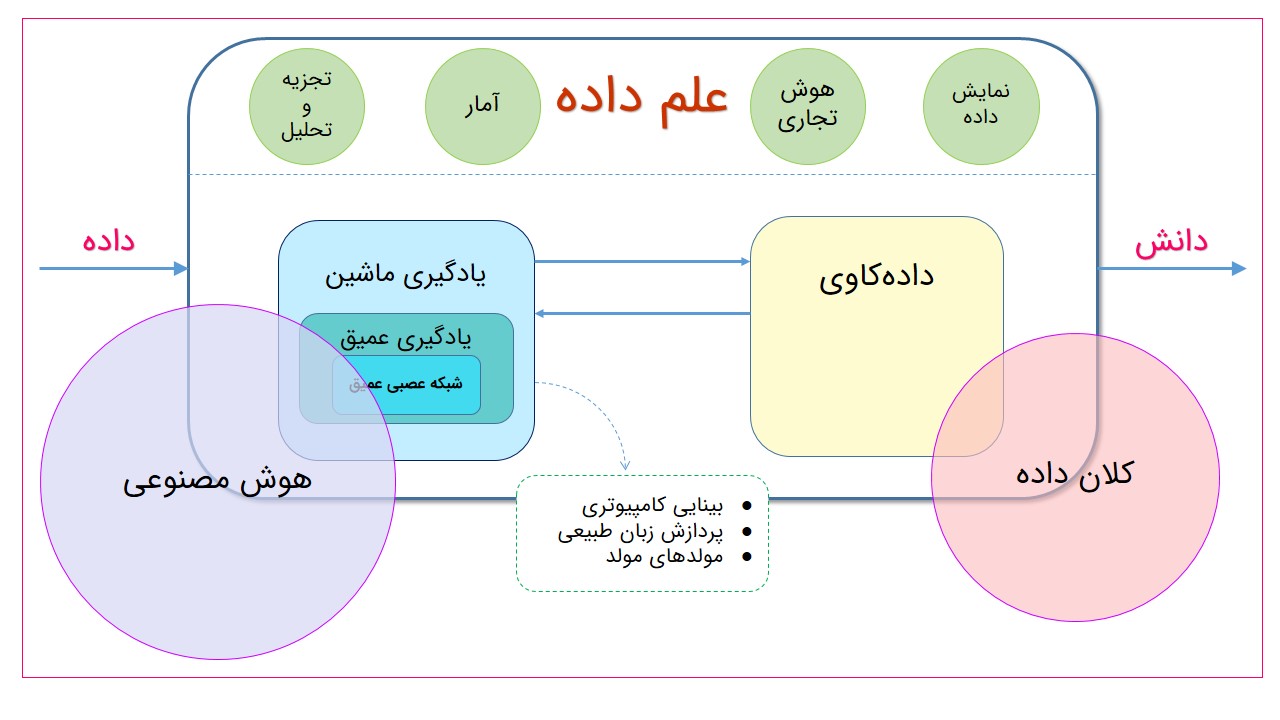
شکل فوق رابطه دقیقتری بین تمام این فاکتورها را نشان میدهد، در مجموع تمام این مفاهیم در خدمت هستند تا دادهی وروردی به بینش تبدیل گردد. در این تصویر به جایگاه علم داده در کنار دو مفهوم هوش مصنوعی و کلان داده اشاره شده است. همانطور که مشخص است مصورسازی داده و هوش تجاری از ابزارهای نمایشی، آمار و تحلیلها از تکنیکهای محاسباتی در علم داده هستند. هوش مصنوعی در مواردی چون یادگیری ماشین و یادگیری عمیق با علم داده اشتراک دارد و هر آنچه هوش مصنوعی رشد پیدا میکند الهامبخش ابزارها و تکنیکهای علم داده خواهد بود. از طرفی نشان میدهد دادهکاوی و یادگیری ماشین رابطهای دو طرفه با یکدیگر دارند؛ بدین شکل که دادهکاوی از یادگیری ماشین استفاده میکند و یادگیری ماشین دادهکاوی را قادر به دریافت نتیجه مینماید. علاوه بر این یادگیری عمیق و شبکه عصبی عمیق مواردی چون بینایی کامپیوتری، پردازش زبان طبیعی و مدلهای مولد (generative models) را تسهیل مینمایند و آنها را به کاربرد میرسانند.
بینایی کامپیوتری (computer vision) سعی دارد تا الگوریتمهای هوشمند را در حوزه پیشبینی دیداری همچون شناسایی اشیا، دستهبندی منظره، درک یکپارچه محیط، شناسایی حرکات انسان و تشخیص اشیا توسعه دهد (۱۳). مدلهای مولد یا زایشی چگونگی تولید داده براساس مدلهای احتمالی را توصیف میکنند (۱۴). یک مدل مولد روشی قدرتمند است که میتواند با استفاده از یادگیری نظارت نشده توزیع هر نوع دادهای را بیاموزد. بیز ساده، مدلهای مارکوف مخفی، تخصیص پنهان دیریکله از نمونههای معروف مدلهای مولد هستند.
منابع:
۱- www.thotwave.com/blog/2017/07/07/difference-between-analytics-and-bigdata-datascience-informatics/
۲- Intelligent agents؛ Harvnb,Poole,Mackworth,Goebel,1998
۳- www.leverege.com/blogpost/the-difference-between-artificial-intelligence-machine-learning-and-deep-learning
۴- www.kdnuggets.com/2016/03/data-science-puzzle-explained.html
۵- Qiu et al, 2016, “A survey of machine learning for big data processing”, EURASIP Journal on Advances in Signal Processing
۶- www.investopedia.com/terms/d/deep-learning.asp
۷- www.quora.com/How-can-Deep-Learning-be-used-in-Data-Mining
۸- XW Chen, X Lin, 2014, big data deep learning: challenges and perspectives. IEEE Access 2, 514–۵۲۵
۹- Najafabadi et al, 2015, Deep learning applications and challenges in big data analytics, Journal of Big Data, 10.1186/s40537-014-0007-7
۱۰- www.thotwave.com/blog/2017/07/07/difference-between-analytics-and-bigdata-datascience-informatics/
۱۱- Federal Financial Supervisory Authority, 2018, Big data meets artificial intelligence: Challenges and implications for the supervision and regulation of financial services, BaFin.
۱۲- www.upfrontanalytics.com/data-mining-vs-artificial-intelligence-vs-machine-learning/
۱۳- vision.stanford.edu/
۱۴- www.quora.com/What-is-a-generative-model
گردآوری: سرور مطیع (s15motie [at] yahoo [dot] com)